
data wrangling को Data cleaning या Data munging भी कहा जाता है, यह डाटा माइनिंग प्रक्रिया की एक स्टेज है। डाटा रैंगलिंग प्रक्रिया द्वारा Raw data को उपयोग करने योग्य डाटा के रूप में बदला जाता है, या यूँ कहें की डाटा पर किसी भी प्रकार का एनालिसिस करने से पूर्व डाटा रैंगलिंग प्रक्रिया को परफॉर्म किया जाता है
डाटा रैंगलिंग द्वारा raw data पर से errors और Incompleteness को हटा कर, उसे reorganiz और data Mapping कर सिस्टम अनुकूल फॉर्मेट में ट्रांसफॉर्म किया जाता है, यानि डाटा को टारगेट सिस्टम की जरुरत के अनुसार ट्रांसफॉर्म और ऑर्गनाइज़ किया जाता है।
दूसरे शब्दों में कहें तो डाटा विभिन्न श्रोतों से प्राप्त होता है, जो की बिलकुल ही Raw फॉर्म में होता है। ऐसे में यदि आज की मार्केटिंग आवश्यकता के लिए उस Raw डाटा का उपयोग करना हो या उस रॉ डाटा में से अपने काम के Inputs निकालने हों, तो पहले उस रॉ डाटा की क्लीनिंग करनी होगी और उसे व्यवस्थित रूप देकर टारगेट सिस्टम के अनुकूल बदलना होगा।
ताकि उस डाटा का उपयोग (BI) बिज़नेस इंटेलिजेंस , बिज़नेस प्रक्रिया को बेहतर करने या किसी दूसरे सिस्टम को एनालाइज करने के लिए लिए किया जा सके, तो Data Wrangling प्रक्रिया के द्वारा ही यह संभव हो पाता है।
यानि एक प्रोफेशनल डाटा एनालिसिस प्रक्रिया को शुरू करने से पहले data wrangling द्वारा डाटा की विश्वशनीयता और सम्पूर्णता को सुनिश्चित किया जाता है।
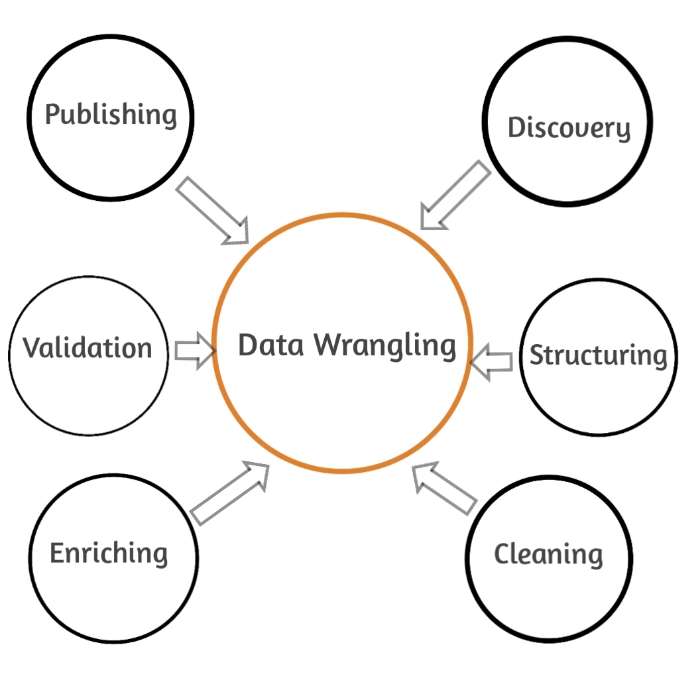
डाटा रैंगलिंग के स्टेप्स (Data wrangling steps in Hindi)
डाटा रैंगलिंग प्रक्रिया के निम्नलिखित 6 स्टेप्स हैं।
(Discovery) डाटा रैंगलिंग प्रक्रिया का सबसे पेहला स्टेप डिस्कवरी है, जिसमे डाटा को समझा जाता है, की आपका डाटा किस प्रकार का है, और बेहतर परिणाम के लिए उसे कैसे एनालाइज किया जा सकता है।
(Data Structuring) पेहले स्टेप को पूरा करने बाद अब आप प्राप्त Raw data को एनालिटिकल मॉडल के अनुसार Structured करेंगे ताकि आगे की स्टेप्स को परफॉर्म किया जा सके।
(data Cleaning) पिछले स्टेप्स द्वारा जब डाटा को स्ट्रक्चर्ड रूप दे दिया जाता है, तो अब अगला स्टेप है, डाटा क्लीनिंग का, जिसमे डाटा पर से डुप्लीकेट डाटा और data errors को हटाया जाता है, यानि इस प्रक्रिया का उद्देश्य डाटा को error मुक्त करना है, ताकि डाटा एनालिसिस पर इसका गलत प्रभाव ना पड़े।
(Enriching Data) इस स्टेप में यह देखा और तैय किया जाता है, की जो भी डाटा आपके पास उपलब्ध है, क्या वह काफी है, या आपको और अधिक डाटा की आवश्यकता है। यदि आप फिर से कुछ नया डाटा इसमें जोड़ते हैं, तो उस डाटा को भी पिछले तीनों चरणों से गुजारा जाता है।
यह एक ऑप्शनल स्टेप है, जिसका उपयोग तभी किया जाता है, जब आपको लगे की डाटा उपयुक्त और काफी नहीं है।
(Validation) डाटा वेलिडेशन प्रक्रिया द्वारा यह चेक किया जाता है, की डाटा Consistent और sufficient है, साथ ही डाटा की quality का भी पता लगा लिया जाता है, यानि वेलिडेशन स्टेप द्वारा डाटा की क्वालिटी और consistency से संबंधित समस्या का पता लगाया जाता है।
(Publishing) यह डाटा रैंगलिंग प्रक्रिया का आख़िरी स्टेप है, जिसमे डाटा वैलिडेट करने के बाद publishing के लिए तैयार हो जाता है। इसमें अपनी आवश्यकता अनुसार डाटा को किसी भी फॉर्मेट में बदला जा सकता है, ताकि दूसरे Users और analysis एप्लीकेशन के लिए डाटा को आगे भेजा जा सके।
नोट:- दोस्तों आपने Data wrangling के बारे में पढ़ा Data wrangling in Hindi और data wrangling steps क्या हैं। यदि आपको यह जानकारी अच्छी लगी है, तो इसे अपने दोस्तों को भी शेयर करें धन्याद।